Тема 3 — Въведение в паралелната обработка
Паралелната обработка е фундаментален отговор на физическите ограничения на последователното изчисление. Докато технологичното усъвършенстване — от ламповата електроника до VLSI — е движело производителността нагоре в продължение на десетилетия, крайната скорост на разпространение на електромагнитния сигнал поставя непреодолима горна граница пред тактовата честота. Именно тази граница прави паралелната обработка не само желателна, но и неизбежна за удовлетворяване на изчислителните нужди на съвременната наука, индустрия и търговия.
1. Необходимост от паралелна обработка
Историческото развитие на компютърната архитектура се е стремяло към две основни цели: увеличаване на производителността и подобряване на надеждността. За постигането им са прилагани два взаимодопълващи се подхода — технологично усъвършенстване и промяна в организацията на изчислителния процес.
В продължение на първите тридесет години след появата на компютъра акцентът е поставян главно върху технологията: намаляване на продължителността на процесорния цикъл от 500 ns при IBM 360/50 (1965 г.) до 12.5 ns при CRAY-1 (1976 г.) и 9.5 ns при CRAY X/MP (1982 г.). Понастоящем водещите производители Intel и AMD достигат тактови честоти от порядъка на 3 GHz. Независимо от тези постижения, скоростта на светлината е фундаменталното ограничение на подхода — токовете не могат да се разпространяват по-бързо от физиката позволява.
Ето защо вниманието е насочено към втория подход: радикална промяна в организацията на изчислителния процес чрез реализирането на паралелни компютри. Идеята за паралелни изчисления изпреварва самия компютър с повече от век — тя е формулирана от генерал Л. Менебрия, съратник на Чарлз Бабидж, още през 1842 г. Интензивни изследвания обаче започват едва в края на 50-те и началото на 60-те години на XX в., а практическата реализация става възможна с появата на VLSI и микропроцесорите.
Паралелните компютри предлагат три ключови предимства пред конвенционалните:
- Значително по-висока скорост на обработка — съвременните паралелни системи достигат производителности от порядъка на няколко GFLOPS и повече, необходими за геофизиката, молекулярната биология, моделирането на електронни схеми и обработката на сигнали.
- Повишена надеждност — при отказ на отделен процесор системата продължава работа с намалена, но реална производителност, вместо да спира напълно.
- По-високо отношение производителност/цена — като правило с порядък по-добро спрямо еквивалентен последователен компютър.
2. Нива на паралелност
Паралелизмът в компютрите може да се реализира на различни нива — от цялостни задания до отделни битове в логическите схеми. По-дълбоките нива обикновено изискват по-специализиран хардуер, но носят и по-висок потенциал за ускорение.
- На ниво задания — паралелно изпълнение между отделни задания или между техните фази. Изисква многомашинна система от слабо свързани или несвързани компютри. Представлява интерес преди всичко за системните администратори.
- На ниво програми — паралелно изпълнение между подпрограми или в рамките на цикли. Изисква компютър с няколко процесора, взаимодействащи чрез обща памет или чрез обмен на съобщения.
- На ниво команди — съвместяване на различните фази на изпълнение на последователни команди. Реализира се чрез конвейерна обработка и представлява паралелизъм от ниско ниво.
- На ниво машинна дума и аритметични операции — паралелно изпълнение между елементите на векторни операции (характерно за векторните компютри с операционни конвейери) или вътре в логическите схеми на аритметичното устройство. На практика всички съвременни процесори реализират паралелизъм поне на това подниво.
В реалния свят едно и също изчислително устройство може едновременно да съчетае паралелност на повече от едно ниво — например пространствен паралелизъм (множество процесори) с паралелизъм във времето (конвейерна обработка), което мултиплицира общия ефект.
3. Оценка на производителността
3.1 Коефициент на ускорение и ефективност
След въвеждане на паралелна обработка естественият въпрос е: с колко се е увеличила производителността? За отговор се използва коефициентът на ускорение (speedup):
където е времето за решаване на задачата на еднопроцесорен компютър, а — времето на паралелен компютър с процесора с еднакви характеристики. За да има смисъл от паралелизма, трябва .
Ефективността на използване на процесорите е:
Колкото е по-близко до 1, толкова повече процесори са заети по цялото времетраене на задачата. При реални системи зависимостта преминава през три характерни зони: линейно нарастване (близко до идеалното), насищане и дори спад при прекалено голям брой процесори поради режийните разходи за синхронизация и разрешаване на конфликти.
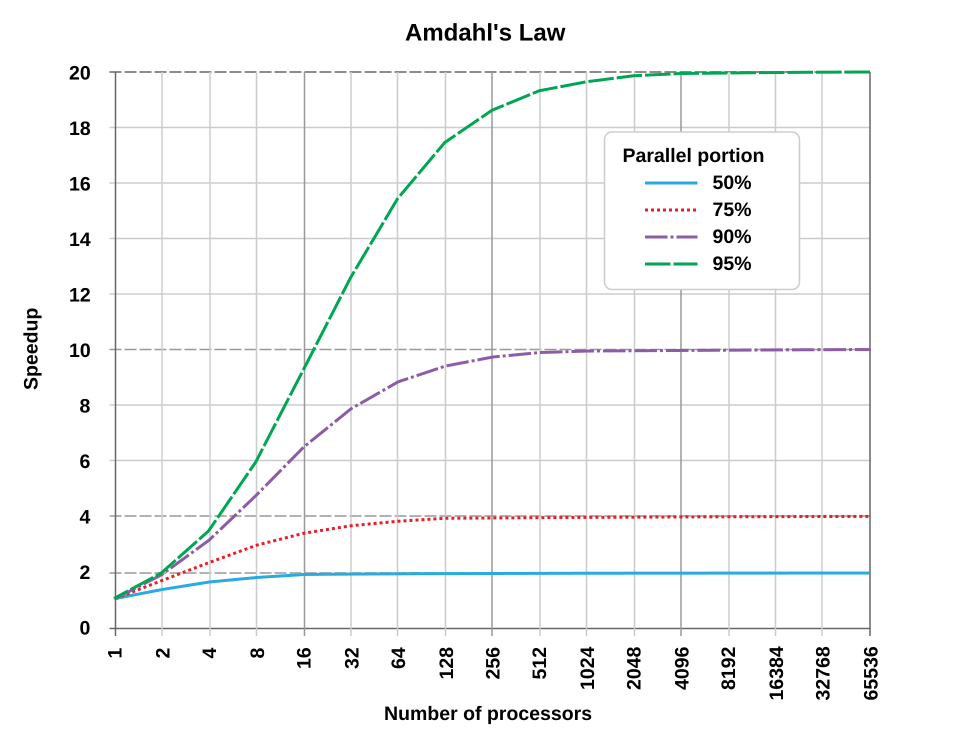 Теоретичното ускорение според закона на Амдал при различни дялове паралелно изпълняем код. При 95% паралелизъм максималното ускорение с 2048 процесора е около 20×. (Wikimedia Commons)
Теоретичното ускорение според закона на Амдал при различни дялове паралелно изпълняем код. При 95% паралелизъм максималното ускорение с 2048 процесора е около 20×. (Wikimedia Commons)
4. Модели на мащабируемостта
Мащабируемостта описва способността на паралелен компютър да увеличава производителността си пропорционално с добавянето на нови процесори. Два основни модела дефинират рамката на тази дискусия.
4.1 Закон на Амдал — ограничение по размер на задачата
През 1967 г. Gene Amdahl формулира своя закон: последователната част на програмата ограничава отгоре коефициента на ускорение. Ако е делът от времето, изразходван за последователни операции, и за паралелни, при нормировка , то:
Ускорението асимптотично се доближава до независимо от броя процесори. Например при и едва 1% последователен код (), , а — песимистичен резултат, показващ, че производителността е диктувана от задачата, а не от хардуера.
4.2 Закон на Густафсон — ограничение по фиксирано време
През 1987 г. John Gustafson (известен и с участието на Barsis) предлага алтернатива: по-реалистично е да се приеме, че времето за изпълнение е константа, а размерът на задачата се мащабира с броя процесори. При означения като времетраене на паралелния компютър:
При и : , . Коефициентът расте почти линейно, защото паралелната програма е настроена да запълва наличното процесорно време с по-голяма задача — подход, много по-близък до реалните приложения.
5. Класификация на паралелните компютри
Всяка добра класификация трябва да обхваща всички съществуващи архитектури, да диференцира съществено различните структури и да класифицира всеки компютър еднозначно.
5.1 Класификация на Флин
Едно от първите и все още най-широко използвано разграничение е предложено от Michael Flynn през 1966 г. То се базира не на физическата структура, а на начина, по който командите се свързват с обработката на данните. Flynn въвежда понятието поток — последователност от елементи (данни или команди), обработвани от процесорите. Четирите класа произтичат от комбинацията единичен/множествен поток команди срещу единичен/множествен поток данни:
SISD (Single Instruction Stream, Single Data Stream) — класическият фон Ноймански компютър с едно управляващо устройство и едно изпълнително. Всяка команда обработва един елемент данни.
SIMD (Single Instruction Stream, Multiple Data Stream) — един поток команди, но векторен: той инициира едновременни операции върху множество елементи данни. Типични представители са CRAY-1, CRAY-2, ILLIAC-IV и съвременните GPU. Flynn отбелязва ключови трудности: поддържане на комуникация между изчислителните елементи, съответствие между размера на вектора и масива от процесори, обработка на невекторни операции и бездействие на процесори при условни преходи.
MISD (Multiple Instruction Stream, Single Data Stream) — множество потоци команди обработват един поток данни. Практическото приложение е ограничено; конвейерната архитектура може условно да се отнесе тук, но по-естествено принадлежи към SIMD.
MIMD (Multiple Instruction Stream, Multiple Data Stream) — множество независими процесори изпълняват различни програми върху различни данни. Включва всички форми на мултипроцесорни конфигурации — от обединени работни станции до матрици от процесори. Комуникацията се осъществява чрез обща памет или чрез съобщения. Предимството е огромната гъвкавост и мощ; недостатъците включват линейно нарастване на цената и нарастваща конфликтност при достъп до общи ресурси.
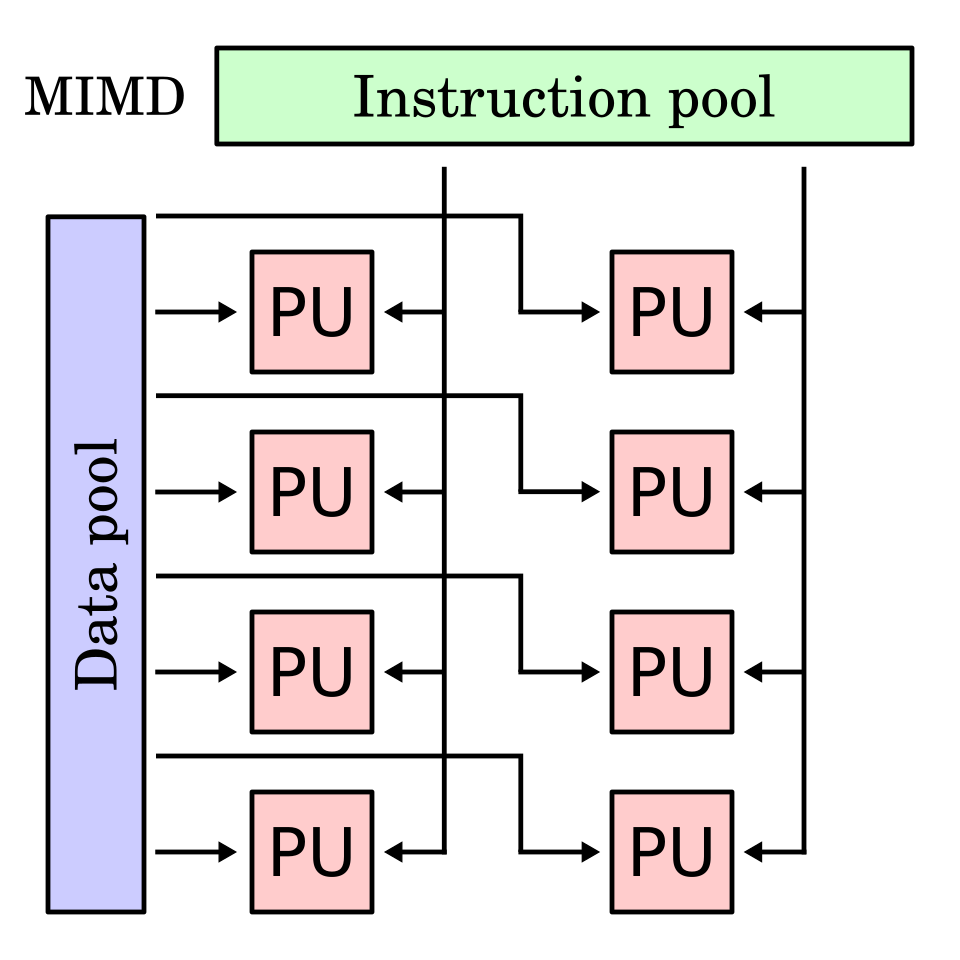
MIMD (Multiple Instruction, Multiple Data) — доминиращата архитектурна категория в съвременните мултипроцесорни системи; всеки процесор изпълнява собствен поток команди върху собствен поток данни. (Wikimedia Commons)
5.2 Разширения на класификацията на Флин
Основната схема е елегантна, но прекалено широка — в един клас попадат компютри с твърде различна архитектура. Предложени са две разширения:
- По начин на обработка (битово/словово): добавянето на суфикс
/B(bit-serial) или/W(word) генерира осем класа, напр. SIMD/B и SIMD/W. - Класификацията на Foutain: отчита типа автономия на процесорите (операционна, адресна, мрежова), топологията на свързване и формата на данните, което дава значително по-детайлна картина.
5.3 Допълнителни класификационни критерии
- По функционално предназначение: компютри за числени инженерни изчисления срещу системи за изкуствен интелект и бази знания.
- По способа за управление: управление по поток управляващи оператори (control driven), по поток данни (data driven) или по поток заявки (demand driven). Преобладаващ е първият тип.
- По степен на свързаност: силно свързани системи (общa шина), слабо свързани (собствена памет и ОС на всеки компютър) и мрежово свързани (локална мрежа, пакетна комуникация).
- По степен на равноправие: “автократични” системи с главен управляващ процесор срещу “егалитарни” системи, в които всички процесори са равноправни.
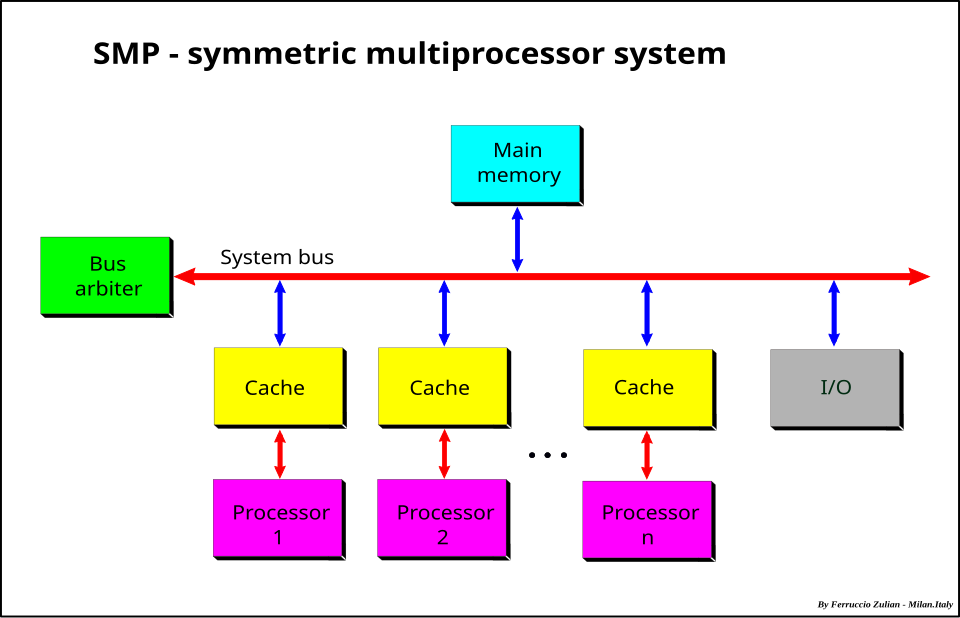
Симетрична многопроцесорна система (SMP) — пример за силно свързана (tightly coupled) конфигурация: всички процесори имат равноправен достъп до обща памет чрез системна шина, с локална кеш памет при всеки. (Wikimedia Commons)
6. Разпределена обработка
Изчислителните мрежи, изградени от територално обособени центрове, представляват специфична форма на паралелна обработка, съществено различна от тясно свързаните мултипроцесорни системи. Центровете функционират автономно и взаимодействат чрез канали за връзка; информацията се предава в пакети или съобщения.
Разграничаването между разпределена изчислителна система и изчислителна мрежа се основава на степента на зависимост и локализация на компонентите: ако са относително зависими и физически близки, системата е разпределена; ако са достатъчно сложни и независими, говорим за различни машини, обединени в мрежа.
Практически пример за разпределено изчисление е проектът SETI@home, при който милиони компютри — включени в Интернет — паралелно обработват астрономически данни, докато процесорите им бездействат. Програмата работи с максимално нисък приоритет и е практически невидима за потребителя.
Ключово практическо правило: когато задачата е ограничена по размер, по-ефективна е разпределената обработка; когато е ограничена по време, по-добро е използването на централизирана паралелна система (суперкомпютър).
Резюме
- Паралелната обработка е неизбежен отговор на физическите ограничения на тактовата честота; реализира се на нива задания, програми, команди и аритметични операции.
- Коефициентът на ускорение измерва печалбата от паралелизма; ефективността показва средното натоварване на процесорите.
- Законът на Амдал определя горна граница на ускорението, диктувана от последователната част на програмата; законът на Густафсон показва, че при мащабируеми задачи ускорението расте почти линейно с броя процесори.
- Класификацията на Флин (SISD, SIMD, MISD, MIMD) е фундаменталният стандарт за таксономия на компютърните архитектури, основан на потоците от команди и данни.
- Разпределената обработка чрез изчислителни мрежи е подходяща за задачи с фиксиран размер; суперкомпютрите — за задачи с фиксирано критично времетраене.